
什么是TLD
TLD(Tracking-Learning-Detection)是一种针对单一目标的长时间跟踪算法(long-term tracking)。对于一段长时间的视频,我们希望对其中某个目标进行跟踪(一个人,一辆车,或者仅仅是一块运动的区域),首先在某一帧画面规定一个矩形框,框住的区域就是我们关注的目标,那么该算法做的事就是在接下来的视频中不断跟踪这个目标,无论该物体是否暂时离开画面,或者被遮挡,或者发生形变,都不会影响继续的跟踪。示例图:

要实现这样的长时间跟踪,有一些问题是不得不面对的。其中最关键的问题是,如果跟踪的目标暂时离开画面,那么当它重新出现的时候,如何检测?除了这点,一个成功的长时间跟踪还要考虑到尺度、光照变化,复杂背景,实时检测等问题。
TLD的是如何工作的
传统的长时间跟踪可以有两种方式:跟踪(Tracking)或者检测(Detection)。对于一般的跟踪算法,只需要进行一次初始化,就可以估计目标的运动。不过单一的跟踪算法有一个致命的缺陷:当目标离开画面再重新出现,或者运动过程中被遮挡,跟踪就会失效。这时有人会想到用检测方法来实现对目标的跟踪,即对于每一帧画面,都检测是否有目标存在。这种方法的缺陷在于:需要一个离线的训练过程,也就是说需要目标的训练集,对于陌生的目标,检测不能进行。
那么现在问题来了:是不是可以把Tracking与Detection结合起来,Tracker为Detector提供训练数据,Detector可以为Tracker进行重新初始化?
TLD做的就是这样一件事情。它分为三个模块:Tracking-Learning-Detection,每个模块独立运行又互相协作。如图所示:
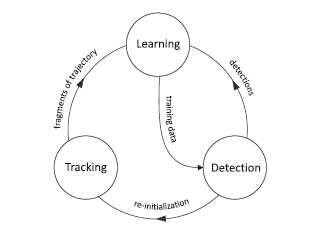
1.对于跟踪模块,它假设目标在帧与帧之间的运动是连续并且可见的,从而估计出目标在下一帧的位置(这里用到的是光流法)。并将估计到的区域提交给学习模块。
2.对于检测模块,它根据学习模块提供的训练集进行训练,对每一帧画面进行检测(这里用到了随机森林方法),将检测到的区域反馈给学习模块,并利用检测到的区域对跟踪模块进行重新初始化。
3.对于学习模块,它是整个TLD系统的“大脑”,是核心部分。在得到跟踪模块以及检测模块提供的样本之后,它要对这两种样本进行一种“取舍”(这里用到的是一种PN-Learning学习方法),再把得到的结果提供给检测模块。可以说,跟踪与检测模块提供的样本是可以互相修复互相纠正的,以达到错误率最小的效果。
未完待续
接下来我会针对这三个模块分别进行总结。