
Detector——检测器
检测器假设目标在某一帧只会出现在一个位置,首先在当前帧画面规定若干个Scanning-window grid(扫描窗),这些扫描窗的大小是根据程序初始化时给定的bounding-box按照一定比例缩放得到的。之后检测器会对每一个扫描窗进行分类,最终得到标记为“前景”的扫描窗。
扫描窗的初始化

图中所示大致就是扫描窗的分布设计,不过这只是一种扫描窗的尺度,实际上扫描窗是有若干种尺度变化的,从代码中可以看出,尺度变化的比例为1.2,而同一尺度扫描窗的位移变化为宽高的10%。
const float SHIFT = 0.1; //扫描窗口步长为 宽高的 10%
//尺度缩放系数为1.2 (0.16151*1.2=0.19381),共21种尺度变换
const float SCALES[] = {0.16151,0.19381,0.23257,0.27908,0.33490,0.40188,0.48225, 0.57870,0.69444,0.83333,1,1.20000,1.44000,1.72800, 2.07360,2.48832,2.98598,3.58318,4.29982,5.15978,6.19174};
同时,对于每一个扫描窗,还要计算它与原bounding-box的重叠程度,计算方式为两窗交集/两窗并集。最终得到重叠程度最大的10个窗口记为good_boxes,重叠程度小于0.2的记为bad_boxes。根据good_boxes和bad_boxes得到正负样本。这里要对good_boxes做一些仿射变换,以增加鲁棒性,具体方法如下:
对每个good_box,进行±1%范围的偏移,±1%范围的尺度变化,±10%范围的平面内旋转,并且在每个像素上增加方差为5的高斯噪声(确切的大小是在指定的范围内随机选择的),那么每个box都进行20次这种几何变换,那么10个box将产生200个仿射变换的bounding box,作为正样本。
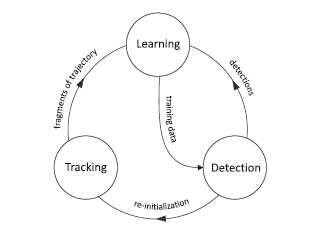
级联分类器
这里检测器使用了3个级联的分类器,被测试的扫描窗只有通过这3个级联的分类器,才会被分类为前景。
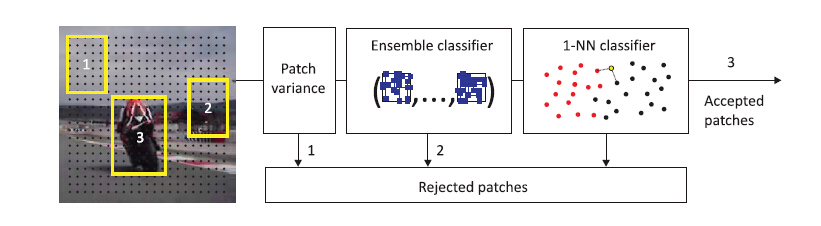
1.方差分类器
这里的方差分类器很好理解,首先利用积分图求出当前要分类扫描窗的灰度值期望,再根据期望计算出方差,与原bounding-box的方差作对比,方差小于bounding-box方差的50%的扫描窗都不会通过这个分类器。(这里的阈值是可以调整的)
2.Ensemble Classifier(集合分类器)
这里作者采用了一种类似于随机森林的思想,称它为“Fern”。关于这个“Fern”结构,可以参考这篇博文。
该博文参考的是2010年的论文,那时原作者在特征提取这里使用的是2bitBP特征,博文里也做了介绍。不过似乎作者后来做了改进,我反复看了论文和代码,在2012年的论文和最新版本的代码里,作者没有使用这种特征,取而代之的是一种pixel comparisons作为图像的特征。
这种特征的大致思想是:对于每一种尺度的扫描窗,规定N*M对像素点,每一对像素点是对应且位置固定的。这里的N是决策树的数量,M为每一个决策树的“层数”。每一对像素点的灰度值进行比较,可以得出0或者1,这样每一个扫描窗对应每一个决策树就有一个M位的特征码,可以对应到该树的叶子节点上。

//集合分类器基于n个基本分类器,每个分类器都是基于一个pixel comparisons(像素比较集)的;
//pixel comparisons的产生方法:先用一个归一化的patch去离散化像素空间,产生所有可能的垂直和水平的pixel comparisons
//然后我们把这些pixel comparisons随机分配给n个分类器,每个分类器得到完全不同的pixel comparisons(特征集合),
//这样,所有分类器的特征组统一起来就可以覆盖整个patch了
//用随机数去填充每一个尺度扫描窗口的特征
for (int i=0;i<totalFeatures;i++){
x1f = (float)rng;
y1f = (float)rng;
x2f = (float)rng;
y2f = (float)rng;
for (int s=0; s<scales.size(); s++){
x1 = x1f * scales[s].width;
y1 = y1f * scales[s].height;
x2 = x2f * scales[s].width;
y2 = y2f * scales[s].height;
//第s种尺度的第i个特征 两个随机分配的像素点坐标
features[s][i] = Feature(x1, y1, x2, y2);
}
}
代码里给出的N为10,M为13。对这10个分类器训练时,每个叶子结点可以得到一个后验概率:#p/(#p+#n),代表落到这个叶子节点的前景占落到这个叶子节点的所有扫描窗的比例。那么当一个待分类扫描窗通过这个决策树时,落在某个叶子节点上,该节点的后验概率代表着这个待分类扫描窗有多大的概率为前景目标,再统计该待分类扫描窗通过所有10个分类器分别得到的概率的平均值,如果超过一个阈值,那么可以让它通过集合分类器。
3.Nearest Neighbor Classifier(最近邻分类器)
这里引用一下这篇博客里的一部分:

未完待续
至此,如果一个扫描窗通过了这三个级联分类器,则视它为检测器检测到的目标。
由于本人对这部分也只是初探,可能有理解不对的地方,之后会不断完善。